
Little John Drop Tables
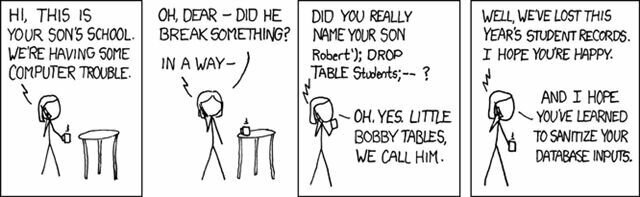
A frequently asked question on the and on the IRC channel (#sqlalchemy on freenode) is how to go about implementing a custom Table object, which automatically adds specific columns to every table.
For example, if you want all of your tables to contain created_at and updated_at columns, you might be inclined to try and subclass Table. Unfortunately, Table is not easy to subclass due to the metaclass which controls its creational pattern. Instead we can use a factory function to handle it for us:
def TimeStampTable(*args, **kwargs):
args = args + (
Column('created_at', DateTime, nullable=False, default=datetime.now),
Column('updated_at', DateTime, onupdate=datetime.now)
)
return Table(*args, **kwargs)
This function simply adds the extra columns to the Table args and returns the new Table. We can then use it in our code like so:
my_table = TimeStampTable('my_table', metadata,
Column('id', Integer, primary_key=True)
)
I’ve been using this approach on a recent project and it works quite well. This idea comes from Mike Bayer.
Although some people may be aware that SQLite supports Full-Text Search (FTS) I would guess that not many have much experience with getting it setup and using it. I only base this information on the fact that the documentation on the SQLite site as well as what I could find on the Googles has been pretty slim. As a result I thought it might would to provide a walkthrough on getting SQLite FTS setup and working. That said I must preface this by saying that the instructions here apply specifically to Mac OS X.
There are a lot of downloads available for SQLite, and that alone can cause some confusion. The thing to keep in mind is that with SQLite you’re really dealing with two parts: the engine and the client. The client is what you use to interact with a SQLite database on the command-line. The engine is the functionality itself and can operate independently of the command-line application.
When it comes to building from source code, there’s a couple of different options as well. First there’s the raw source. But you can also get an amalgamation of the source. This comes in two different flavors: with and without configure scripts and makefiles. You might be curious as to why there are so many options, and it really comes down to being able to support the many different ways people use SQLite. Some folks are only interested in using SQLite in an embedded environment where they might be linking to the engine directly. On the other spectrum some people are using SQLite as a nice testing platform for doing web development. This often requires the SQLite engine, a language-engine interface (dbapi) library, and the client application.
To support FTS within SQLite we have a couple options. SQLite supports the idea of loadable plugin modules. In other words technically we could build the FTS plugin as a dynamically loadable module and then load it before use. The second option is to statically link the FTS plugin into the SQLite source code at build time. This is the approach I will take here.
The source code bundle that we need is the sqlite-amalgamation package. The amalgamation is a single large source code file that contains the entire SQLite implementation, and (as of version 3.5.3) the Full-text search engine. Therefore we want to be sure we get at least release version 3.5.3, just to make things simple. Since there’s two amalgamation packages be sure to select the one that contains the configure script and makefile for building it.
First let’s download and extract the source code:
$ curl -O http://www.sqlite.org/sqlite-amalgamation-3.5.9.tar.gz
$ tar -xvzf sqlite-amalgamation-3.5.9.tar.gz
$ cd sqlite-amalgamation-3.5.9
Now that we have the source we just need to follow the standard process for configuring, compiling, and installing the package. The most important piece is setting configuration parameters appropriately for our platform. Since we want to statically include FTS we need to let the compile know that’s what we plan to do. To do this let’s issue the following command:
$ CFLAGS="-DSQLITE_ENABLE_FTS3=1" ./configure
Note that we’ve enabled FTS3, the latest version.
UPDATE In the original version of this post I suggested changing the default install location to /usr from /user/local. While this will work fine in most cases, it’s not a good thing to do because the underlying operating system is expecting a specific version in the default location. Read the comments below for a good way around overriding the default implementation.
Along these lines, it is important to not get confused by the actual _sqlite3.so library used by Python. On my Mac this is located in the following directory:
/System/Library/Frameworks/Python.framework/Versions/2.5/lib/python2.5/lib-dynload/
It appears that this loadable module simply calls out to the installation in /usr/lib/sqlite3.
The next thing we need to do is actually compile the source and install it. So to do that issue the following two statements:
$ make
$ sudo make install
At this point the latest SQLite should be installed and ready to go on your system. We can verify this two different ways. First let’s verify that the command-line client is in fact updated:
$ sqlite3 --version
3.5.9
If you got something other than that you might want to re-check the steps. Secondly we want to be sure that Python is using the correct version.
Note: I assume Python here because that’s what I’m using but if you’re using a different language you’ll want to modify the checks accordingly. If you are still seeing the older version then you might want to investigate how SQLite is being used in your system. Since it has such a small footprint it’s not uncommon for it to be just bundled in with the program. I know that a search on my system found at least 4 or 5 different installations of SQLite.
$ python
>>> import sqlite3
>>> sqlite3.sqlite_version
'3.5.9'
The above assumes that you’re using Python 2.5+. If you’re using an older version of Python then you will likely be using the pysqlite module.
Once we have SQLite with Full-Text Search capability built in the next step is to just get familiar with the how it all works. I’m not going to go into too much detail here, because there is pretty good usage documentation on the SQLite website.
The key piece is that when you want to utilize FTS on SQLite you need to create your table as a virtual table that utilizes the FTS engine. To do that we need to modify the table creation syntax slightly:
CREATE VIRTUAL TABLE posts using FTS3(title, body);
After we’ve created the appropriate virtual table we can interact with it just like any other table. The difference is we have access to a new keyword syntax: the MATCH operator. The MATCH operator is used to access the FTS functionality.
For instance if we want to find all posts that contain the word python in them we can issue the following SQL:
SELECT * FROM posts WHERE posts MATCH 'python';
This will actually find all posts where the title or body columns contain the text python. In addition to this simple syntax the FTS engine supports things like OR and not (-) types of statements, as well as more complex items like prefix searching:
SELECT * FROM posts WHERE posts MATCH 'py*';
Note: one of the limitations (there’s many) of SQLite’s FTS is that you can’t use more than one MATCH operator in a query. To counteract this just be sure to combine search terms into a single MATCH operator statement and take advantage of the search syntax to do and, or, not, etc…
Well I hope this is enough to get you on your way to using Full-Text Search within SQLite. If you have any special tips, please be sure to leave me a comment.
Just because I spent so much time tracking it down, you can get the SqlAlchemy database-dependent quoted name for a column by doing:
>>> metadata.bind.dialect.identifier_preparer.quote_identifier("test")
'"test"'
>>>
Today there was a question on the #django IRC channel from a user name “Joe” about how to go about retrieving selective fields from a table. Joe had a model structure that looked something like:
class Category(models.Model):
name = models.CharField(max_length=50)
description = models.CharField(max_length=200)
class Link(models.Model):
title = models.CharField(max_length=100)
slug = models.SlugField(prepopulate_from=("title",))
url = models.URLField()
category = models.ForeignKey(Category, null=True, blank=True)
big_ass_notes = models.TextField(blank=True)
updated = models.DateTimeField(editable=False)
user = models.ForeignKey(User)
The issue is that Joe wants to be able to get all Links that are tied to a specific Category but only retrieve select fields. You might want to do something like this if you needed to retrieve a subset of information and you wanted to keep from pulling particularly large fields like BLOBs or Text fields.
At first I had suggested that Joe use the extra() method to retrieve just the fields that he wanted from the Link model without having to pull in all the fields from the model. We tried something like this:
>>> from delinkuent.models import Category, Link
>>> Category.objects.get(pk=1).extra(select={'url': 'delinkuent_link.url'})
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'Category' object has no attribute 'extra'
Well obviously that does not work. The problem is that extra() is a method on the QuerySet. With get() we are only getting a single model instance object. So we tried the following:
>>> from delinkuent.models import Category, Link
>>> Category.objects.get(pk=1).link_set.extra(select={'url': 'delinkuent_link.url'})
[, ]
Well that looks better, but when we check The SQL That Django is Generating we discover the following:
>>> from django.db import connection
>>> connection.queries[-1]['sql']
u'SELECT "delinkuent_link"."id","delinkuent_link"."title","delinkuent_link"."slug","delinkuent_link"."url","delinkuent_link"."category_id","delinkuent_link"."big_ass_notes","delinkuent_link"."updated","delinkuent_link"."user_id",(delinkuent_link.url) AS "url" FROM "delinkuent_link" WHERE ("delinkuent_link"."category_id" = 1) ORDER BY "delinkuent_link"."updated" DESC'
Unfortunately that didn’t work. Notice that all we did was get an extra url item in addition to the url item that was part of the regular SELECT clause. Hence the name extra(). Unfortunately there’s no only().
After working on it a bit, and reviewing my post on Finding Lookup Items That Are Not Used, I realized that I could reverse the logic and approach the problem from a different angle.
Instead of trying to get all Links from the Category, we could get all Links where the Category is the one we want. At first you might think that getting all Links will present a problem since the field we’re trying to ignore is in the Link model. You’re right, except that Django has this cool QuerySet method called values(). The values() method will return a ValuesQuerySet, essentially a QuerySet that evaluates to a list of dictionaries. The values() method accepts a list of field names that you want to include in the ValuesQuerySet dictionary.
Now that we know about values() and reversing the logic, Joe can get what he needs by doing the following:
>>> from delinkuent.models import Category, Link
>>> Link.objects.filter(category__pk=1).values('url')
[{'url': u'http://www.djangoproject.com/'}, {'url': u'http://www.b-list.org/'}]
I always like to take a look at the SQL that Django is generating to make sure I’m getting what I want:
>>> from django.db import connection
>>> connection.queries[-1]['sql']
u'SELECT "delinkuent_link"."url" FROM "delinkuent_link" WHERE ("delinkuent_link"."category_id" = 1) ORDER BY "delinkuent_link"."updated" DESC'
Notice that the big_ass_notes field, the one we are trying to avoid, is not being selected. Perfect!!!
After working through this post it occurred to me that we didn’t really need to reverse the logic. This is where looking at the SQL that is being generated is so helpful. I decided to try it using the FOO_set approach we tried earlier, but with a twist:
>>> from delinkuent.models import Category, Link
>>> Category.objects.get(pk=1).link_set.values('url')
[{'url': u'http://www.djangoproject.com/'}, {'url': u'http://www.b-list.org/'}]
If you notice that when we use FOO_set, if we add on the values() method before it gets evaluated, then we will only get the fields specified in the values method. Here’s the resulting SQL:
>>> from django.db import connection
>>> connection.queries[-1]['sql']
u'SELECT "delinkuent_link"."url" FROM "delinkuent_link" WHERE ("delinkuent_link"."category_id" = 1) ORDER BY "delinkuent_link"."updated" DESC'
Still perfect!!!
Sometimes it takes a bit of work to get where you need to be with the Django ORM. Although, in the end you find that there is a ton of flexibility built into it.
Every once in a while you need a query to return results in a crosstab format. In the past I’ve always approached this in the typical way of using CASE statements to check the key and then outputing the value or returning zero / an empty space. This works well but it can get verbose at times.
Today I ran across a posting on the Rozenshtein Method. It’s a really amazing approach and it’s SQL 92 compliant. The post can be found here:
http://www.stephenforte.net/owdasblog/PermaLink.aspx?guid=2b0532fc-4318-4ac0-a405-15d6d813eeb8
I will not describe it since that’s already done, but I highly recommend you check it out.
Although the example uses the case of crosstabing based on integers, this same method can be used effectively with characters, since every character has an ANSI equivalent. At a client site we used this method to build a crosstab of racial ethnic diversity counts. The end result is kind of a mess, but it works great. For your amusement, here’s a snippet:
SELECT l.id, SUM(l.TotalCount) AS total_count, SUM(l.FemaleCount) AS FemaleCount,
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-801)))) AS "801",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-802)))) AS "802",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-803)))) AS "803",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-804)))) AS "804",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-805)))) AS "805",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-806)))) AS "806",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-807)))) AS "807",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-808)))) AS "808",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-809)))) AS "809",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-810)))) AS "810",
SUM((e.ethniccount)*(1-ABS(SIGN(CONVERT(INT, e.ethniccode)-811)))) AS "811"
FROM RacialEthnicProfilingOnAirlines l
INNER JOIN RacialEthnicCounts e
ON l.id = e.id
INNER JOIN Airlines a
ON l.id = a.id
WHERE a.id IN (SELECT id FROM [Airlines] WHERE [Name] = 'UNTIDY')
GROUP BY l.id
ORDER BY l.id
Today I used a little tidbit that I thought I would pass along. Note that although I’m specifically using SQL Server in these examples the ideas should work regardless. Most often I see two different approaches to using dynamic WHERE clauses in stored procedures:
1. Separate Queries – The first method I see a lot is just setting up separate queries, and you end up seeing code that looks something like this:
IF @p_CompanyID IS NOT NULL AND @p_Name IS NOT NULL BEGIN
SELECT * FROM Company WHERE CompanyID = @p_CompanyID AND Name = @p_Name
END ELSE BEGIN
IF @p_CompanyID IS NOT NULL BEGIN
SELECT * FROM Company WHERE CompanyID = @p_CompanyID
END ELSE BEGIN
IF @p_Name IS NOT NULL BEGIN
SELECT * FROM Company WHERE Name = @p_Name
END ELSE BEGIN
SELECT * FROM Company
END
END
END
This gets ugly really quick.
2. Dynamic SQL – In this approach a query is built up from the parameters and an sp_executesql is used to dynamically execute the query. This can be a very bad approach, especially if the parameters being passed in are generated from some form of user search form input. This is the classic SQL Injection problem.
DECLARE @p_SQL AS NVARCHAR(3500)
SET @p_SQL = 'SELECT * FROM [Company] WHERE 1 = 1'
IF @p_CompanyID IS NOT NULL BEGIN
SET @p_SQL = @p_SQL + ' AND [CompanyID] = ' + @p_CompanyID
END
IF @p_Name IS NOT NULL BEGIN
SET @p_SQL = @p_SQL + ' AND [Name] = ''' + @p_Name + ''
END
exec sp_executesql @p_SQL
This is a lot cleaner than number 1, but it has problems. Also notice the use of the WHERE 1 = 1 statement. That’s a nice little trick to keep you from having to check if you need the AND statement or not.
3. And the Winner Is – Finally, here’s a much better approach, is clean and doesn’t have the sql injection problems:
SELECT * FROM Company
WHERE
((@p_CompanyID IS NULL) OR [CompanyID] = @p_CompanyID)
AND ((@p_Name IS NULL) OR [Name] = @p_Name)
AND ((@p_City IS NULL) OR [City] = @p_City)
AND ((@p_State IS NULL) OR [State] = @p_State)
AND ((@p_Zip IS NULL) OR [Zip] = @p_Zip)
It takes a minute to get your head around what’s going on, but basically we’re saying give me this row if the parameter is not filtered out or the parameter equals the record we’re looking for. You can build this up as I have done here, and keeps things clean. You can see how a simple search form could be implemented as shown above.